afcastro design
---an aging-frequency cache
Man grows old and old points of view are balanced by new points of view.
--- Decheng (Robbie) Fan
Afcastro is a program implementing a cache replacement policy. This cache replacement policy is a combination of the frequency-based mechanism and the aging mechanism. To find afcastro, you can download cmdtools (2010 and onwards) from the winrosh project.
To readers new to a cache, a cache is a mechanism that uses a faster storage medium to store frequently accessed data, as a front-end for a slower storage medium. For example, the computer physical memory often serves as a faster storage medium, as the cache for the hard disk drive. The first level cache of the CPU serves as a faster storage medium for the second level cache, and the second level cache serves as a faster storage medium for the physical memory.
When a cache is working, data are cached as blocks in the faster medium, and map to blocks on the slower medium. Thus, there is an internal block number, which represents the block number in the faster medium, and an external block number, which represents the block number in the slower medium. In this design I call the internal block number the slot number.
Every external block number may be accessed multiple times, at different times. For example, suppose I have a hard disk that can hold 10 blocks of data. And I have a memory that can hold 2 blocks of data. If I access hard disk blocks, there is a sequence of block numbers: 10 4 8 6 10 10 2 3 1 6... Since the memory only has 2 blocks, I need a rule to decide which hard disk blocks should be in the RAM at any time. Thus we have Table 1:
| Slot | Memory content layout (external blocks) | |||||||||
| 1 | 10 | 10 | 8 | 8 | 10 | 10 | 10 | 3 | 3 | 6 |
| 2 | 4 | 4 | 6 | 6 | 6 | 2 | 2 | 1 | 1 | |
The algorithm used to fill the above table is called LRU --- least-recently used. Every time a block is accessed, it goes into the tail of a queue, and if the queue contains the same block previously, it is removed (the queue is not strictly a queue). Suppose the size of the memory is K, then the queue size is K. So for memory size 2, we have a queue size of 2. Although in practice the queue occupies memory space, here we can think of it as very small compared to the size of the whole physical memory, so can be ignored. Once a new block goes in and an old block goes out of the queue, the corresponding internal block is filled with the new external block. In all other cases, the block content is not changed.
It can very efficient to implement an LRU algorithm. A hash table is often good enough. But the LRU algorithm might not be the best cache replacement policy.
Let's look at the other side: a pure frequency-based mechanism. It is like this: for a cached block, whether it is cached purely depends on how many times it has been accessed since the cache was established. This way, what we Chinese call "based on longevity" (Lun Zi Pai Bei) will be in effect. Now let's look at the below sequence of access: 2 3 1 1 4 1 3 5 5 5 Table 2.
| Slot | Memory content layout (external blocks) | |||||||||
| 1 | 2 | 2 | 2 | 2 | 2 | 2 | 3 | 3 | 3 | 5 |
| 2 | 3 | 3 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
By looking at the table above, you can see that the cache is quite rigid. The first time 3 is replaced by 1 at the 4th step because 1 has two occurrences. And 3 replaces 2 at the 7th step because it has two occurrences. Finally, 5 replaces 3 since it has three occurrences.
The drawback of a pure frequency-based cache is that it doesn't consider recency. If a block was accessed three times long long ago, it has the same weight as a block accessed three times recently. On the other hand, LRU considers recency as a very important factor.
The aging-frequency approach makes a balance between the two algorithms. How does it work then? It uses a different way to compute weights of external blocks. The word "aging" means, for an external block, besides weight gained from the most recent access, all previous weight decays as time goes. To make it easier to understand, let's look at Figure 1:
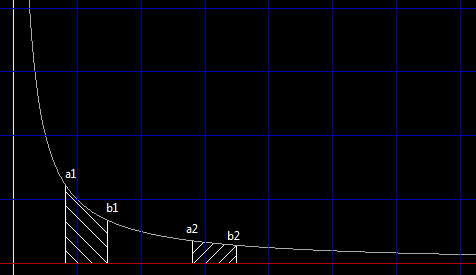
As shown in the image, we can imagine an external block is accessed once in history. Several seconds later, as more blocks have been accessed, its weight decays. We look at its weight, and it's like the area marked below points a1 and b1 in the above image. Another several seconds later, the weight decays more, just like the aree below points a2 and b2. The long curve you see in the image is a hyperbola: made from formula "y = 1 / x".
However, this mathematically simple idea is not efficient to implement --- every time an external block is accessed, the weight of all blocks in the cache should be updated. To implement, I thought of the following approximation: using several queues of different weights. For example, as listed in Table 3:
| Queue | 1st queue | 2nd queue | 3rd queue | 4th queue |
| Size | 1 | 2 | 4 | 8 |
| Weight | 8 | 4 | 2 | 1 |
In the table above, "Size" means the queue size, and "Weight" means the weight of all items in the queue. For every item in the queue, the weight is an approximation to the "1 / x" formula, with scaling in the x-axis. For example, when "x" is 5, the item is in the 3rd queue, and the weight is 2. Let's call the weight of the first queue "w", then "1 / x * w" = "1 / 5 * 8" is nearly 2.
Further more, for an efficient implementation, we can use several data structures to store the metadata. One is a hash table, with external number as the key field, and slot number and weight as the value fields. One is a B-Tree, with weight as the first key field, external block number as the second key field. One is the queues, with the external block number as the field. Once an external block number is inserted, the weights of blocks at queue edges need to be adjusted. When the weight is adjusted, the hash table entry will be updated, and the B-Tree entry will be deleted and re-inserted (because weight is a key field, it cannot be changed). By using this algorithm, the time complexity for each cache access is O(log(n)).
For the implementation I currently use in afcastro, it doesn't use a B-Tree. Instead, it uses a sorted array, which is simpler, while less efficient. If you read the source code, you should read afcache.cs first, because it is the prototype. Then you can read the C language version.
To make the cache more responsive, you can use a smaller value for the first queue size. On the extreme, you can mimick multiple accesses to the same external block. For example, you can always access an external block twice a time, so that the responsiveness can be higher. This makes the cache more like LRU. On the other hand, if you make the first queue size larger, and only accesses one block a time, doing "the normal behavior", then the cache is less responsive, more like a frequency-based cache.
Let's look at the following example (Table 7). The access sequence of external blocks is: 3 4 5 1 2 9 7 3 4 5 1 2 12 10 3 4 5 1 2. The cache size is 6. Queue count: 4, first queue size: 1, first queue weight: 8.
| Slot | Memory content layout | |||||||||||||||||||
| S l o t |
1 | 3 | 3 | 3 | 3 | 3 | 9 | 9 | 9 | 9 | 9 | 9 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 2 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 10 | 10 | 10 | 1 | 1 | 1 | ||
| 3 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | |||
| 4 | 1 | 1 | 1 | 7 | 7 | 7 | 7 | 1 | 1 | 1 | 1 | 3 | 3 | 3 | 3 | 3 | ||||
| 5 | 2 | 2 | 2 | 3 | 3 | 3 | 3 | 3 | 12 | 12 | 12 | 4 | 4 | 4 | 4 | |||||
| W e i g h t |
1 | 0 | 0 | 0 | 8 | 4 | 4 | 2 | 2 | 2 | 2 | 10 | 6 | 6 | 4 | 3 | 3 | 3 | 11 | 7 |
| 2 | 0 | 0 | 0 | 0 | 8 | 4 | 4 | 2 | 2 | 2 | 2 | 10 | 6 | 6 | 4 | 3 | 3 | 3 | 11 | |
| 3 | 8 | 4 | 4 | 2 | 2 | 2 | 2 | 10 | 6 | 6 | 4 | 3 | 3 | 3 | 11 | 7 | 7 | 5 | 4 | |
| 4 | 0 | 8 | 4 | 4 | 2 | 2 | 2 | 2 | 10 | 6 | 6 | 4 | 3 | 3 | 3 | 11 | 7 | 7 | 5 | |
| 5 | 0 | 0 | 8 | 4 | 4 | 2 | 2 | 2 | 2 | 10 | 6 | 6 | 4 | 3 | 3 | 3 | 11 | 7 | 7 | |
| 7 | 0 | 0 | 0 | 0 | 0 | 0 | 8 | 4 | 4 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 1 | 1 | |
| 9 | 0 | 0 | 0 | 0 | 0 | 8 | 4 | 4 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 1 | 1 | 1 | |
| 10 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 8 | 4 | 4 | 2 | 2 | 2 | |
| 12 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 8 | 4 | 4 | 2 | 2 | 2 | 2 | |
As marked out in light cyan background, there are 15 disk reads through out the process of 19 logical reads. The cache miss rate is quite high. Table 8 shows the situation when the first queue size is 8, making the cache less responsive ("slower").
| Slot | Memory content layout | |||||||||||||||||||
| S l o t |
1 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
| 2 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | ||
| 3 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | |||
| 4 | 1 | 1 | 9 | 9 | 9 | 9 | 9 | 9 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | ||||
| 5 | 2 | 2 | 7 | 7 | 7 | 7 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |||||
| W e i g h t |
1 | 0 | 0 | 0 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 16 | 12 | 12 | 12 | 12 | 12 | 12 | 20 | 16 |
| 2 | 0 | 0 | 0 | 0 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 16 | 12 | 12 | 12 | 12 | 12 | 12 | 20 | |
| 3 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 16 | 12 | 12 | 12 | 12 | 12 | 12 | 20 | 16 | 16 | 16 | 16 | |
| 4 | 0 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 16 | 12 | 12 | 12 | 12 | 12 | 12 | 20 | 16 | 16 | 16 | |
| 5 | 0 | 0 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 16 | 12 | 12 | 12 | 12 | 12 | 12 | 20 | 16 | 16 | |
| 7 | 0 | 0 | 0 | 0 | 0 | 0 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 4 | 4 | 4 | 4 | 4 | |
| 9 | 0 | 0 | 0 | 0 | 0 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 4 | 4 | 4 | 4 | 4 | 4 | |
| 10 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 8 | 8 | 8 | 8 | 8 | 8 | |
| 12 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | |
Compared with Table 7, where there are 15 disk reads, in Table 8 there are only 9 disk reads for the cache, which means the hit rate is much higher. However, note that the actual number of disk reads is not like shown in the cache --- there should be temporary working area for the reading of blocks that will not be kept in the cache. This requires another memory block.
As we have seen, raising the first queue size can result in less responsiveness. Trivially, we can understand that raising the queue size results in behavior nearer to a frequency-based cache.
However, what about the resemblance between Table 1 and LRU? Let's simulate it in Table 9.
| Slot | Memory content layout | |||||||||||||||||||
| S l o t |
1 | 3 | 3 | 3 | 3 | 3 | 9 | 9 | 9 | 9 | 9 | 1 | 1 | 1 | 1 | 1 | 4 | 4 | 4 | 4 |
| 2 | 4 | 4 | 4 | 4 | 4 | 7 | 7 | 7 | 7 | 7 | 2 | 2 | 2 | 2 | 2 | 5 | 5 | 5 | ||
| 3 | 5 | 5 | 5 | 5 | 5 | 3 | 3 | 3 | 3 | 3 | 12 | 12 | 12 | 12 | 12 | 1 | 1 | |||
| 4 | 1 | 1 | 1 | 1 | 1 | 4 | 4 | 4 | 4 | 4 | 10 | 10 | 10 | 10 | 10 | 2 | ||||
| 5 | 2 | 2 | 2 | 2 | 2 | 5 | 5 | 5 | 5 | 5 | 3 | 3 | 3 | 3 | 3 | |||||
The behavior of the LRU cache is as shown in the above table. Among them, there are 19 disk reads. The cache miss rate is 100%. This is because the LRU algorithm is too responsive, even worse than the first example of aging-frequency cache. However, it still has its advantage: easy to implement, and can be implemented to be of O(1) time complexity so is very fast, and uses less metadata space than the aging-frequency cache.
Next: discuss different responsiveness (more like LRU or more like frequency).
This article discussed a cache mechanism named aging-frequency cache, and compared it to LRU cache and frequency-based cache. There are many other cache replacement policies: working set, clock, clock-pro, etc. They're useful, but are out of the scope of this article. For those, please search online and you can find abundant resources about them.